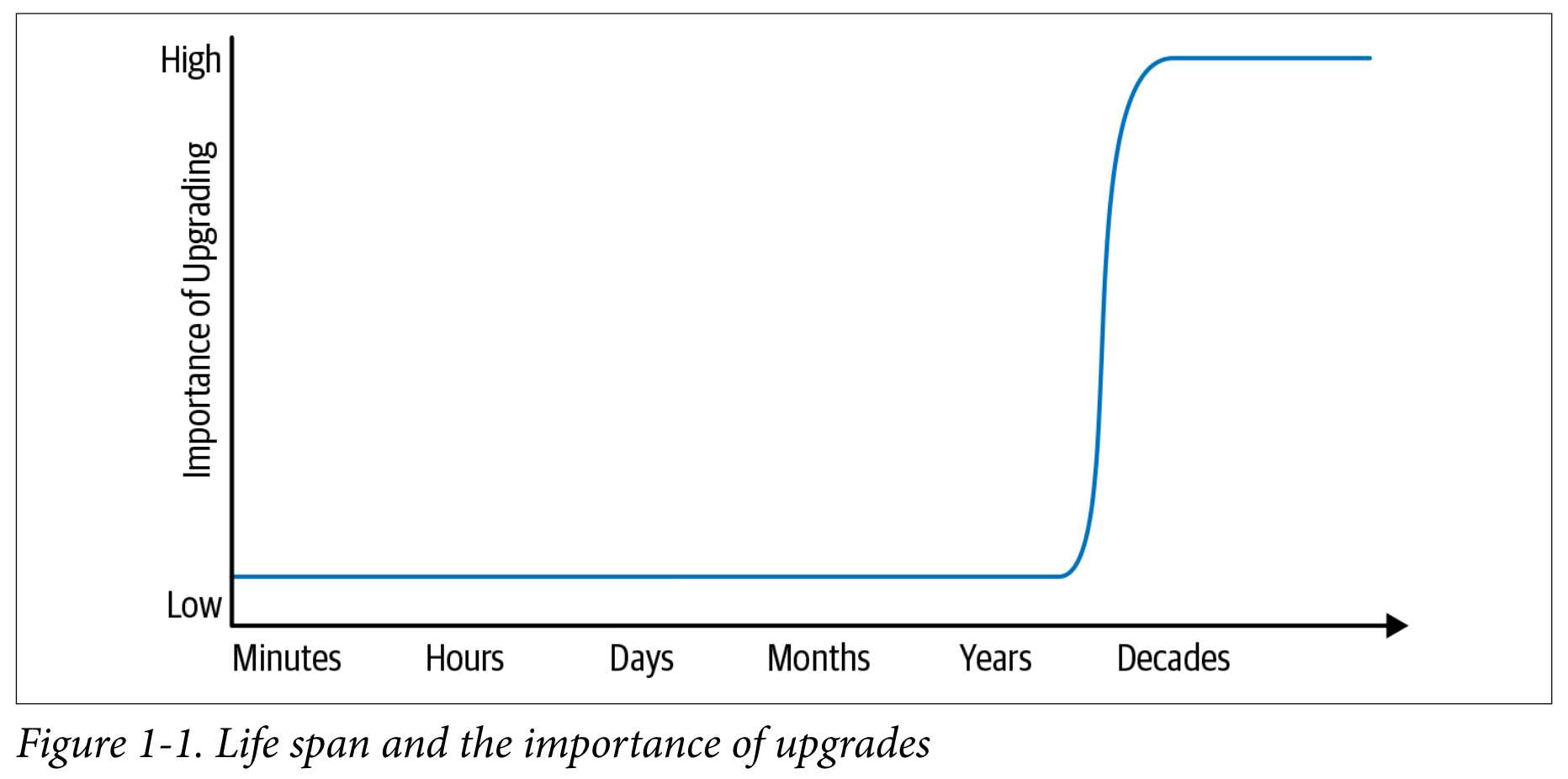
过去十年里,Ceph 一直是在本地文件系统的基础上实现。这个是目前大部分分布式文件系统的选择,因为这样可以利用这些实际环境验证过的代码。然而,Ceph 的经验告诉我们这么做也是有代价的——首先,实现一个零开销的事务机制会很困难;其次,本地的元数据性能会极大影响分布式系统;第三支持新的存储硬件会变得很慢。
Ceph 通过一个新存储后端 BlueStore 来解决这些问题,BlueStore 设计为直接在块设备上运行。在其面世的短短两年里,BlueStore 已经被 70% 的生产客户所采用。通过运行在用户态和对 IO 栈的完全控制,BlueStore 实现了高效的元数据空间和数据校验、EC 数据快速覆写、在线压缩、减少了性能的波动而且避免了一系列本地文件系统的隐患(pitfalls)。最后,通过 BlueStore 还让支持一些原本不支持的存储硬件成为可能。
介绍
后端存储采用文件系统的好处:
- 无需自行解决数据持久和块分配的问题
- 提供熟悉的 POSIX 接口和抽象(文件、目录)
- 可以使用
ls、find这些常用工具来管理
Ceph 开发 BlueStore 几个主要原因:
- 难以在现有文件系统上实现高效的事务操作。
现有的实现要么有很高的性能损失、要么功能有限、要么接口或实现过于复杂,总之都没有直接集成到文件系统里。
Ceph 使用用户态的 WAL 来实现,或者一个支持事务的 KV 存储,但性能都不能满意
-
本地文件系统的元数据性能极大影响分布式层。具体来说,Ceph 需要快速枚举(enumerate)有几百万条目的目录,但 Btrfs 和 XFS 都支持的不够好;如果拆分目录(directory splitting )来减小一个目录内的文件数量,这个操作在文件系统上有成本极大,会拖垮整个系统的性能
-
因为文件系统本身的过于成熟,会导致它对新存储硬件的支持非常慢。例如用来解决 HDD 容量问题的 SMR,用来解决 SSD 的 FTL 层性能损失的 ZSS SSD 都难以支持
BlueStore 的创新之处包括:
- 用 KV 数据库保存像 extent bitmap 这类底层的文件系统元数据,用来避免磁盘格式(on-disk format)的变化和减少实现的复杂度;
-
通过接口设计优化克隆操作,减小 extent refreence-counting 的成本;
-
BlueFS,一个用户态文件系统,让 RocksDB 在裸设备上跑得更快
-
每 TB 消耗 35MB 内存的空间分配器(space allocator)
除此之外,这篇文章还做了一些实验评估从 FileStore 转到 BlueStore 中一些性能的影响因素,例如日志文件系统的影响、日志双写的影响、拆分目录性能的影响和原地更新的影响(与 COW 相反)。
背景
分布式文件系统,无论是 Lustre、GlusterFS、OrangeFS、BeeGFS、XtreemFS 还是之前的 Ceph,都有几个关键需求:
- 高效的事务
-
快速的元数据操作
-
(可能不是通用的)对未来的不向后兼容的存储硬件的支持
因为大部分文件系统按 POSIX 标准实现,因此缺乏事务概念,因此分布式文件系统往往通过 WAL 或者基于文件系统的内部事务机制实现(Lustre)。
无法高效的列举目录内容或者 hanle 海量小文件也是分布式存储使用本地文件系统的一个痛点,为此分布式文件系统就需要通过元数据缓存、哈希、数据库或对本地文件系统打 patch 来解决。
根据硬件供应商的预测,2023 年半数的数据中心将使用 SMR HDD。此外 ZNS SSD 能够通过不提供 FTL 来避免 gc 带来的不可控的延迟。像这种新硬件也是 Ceph 希望支持的。
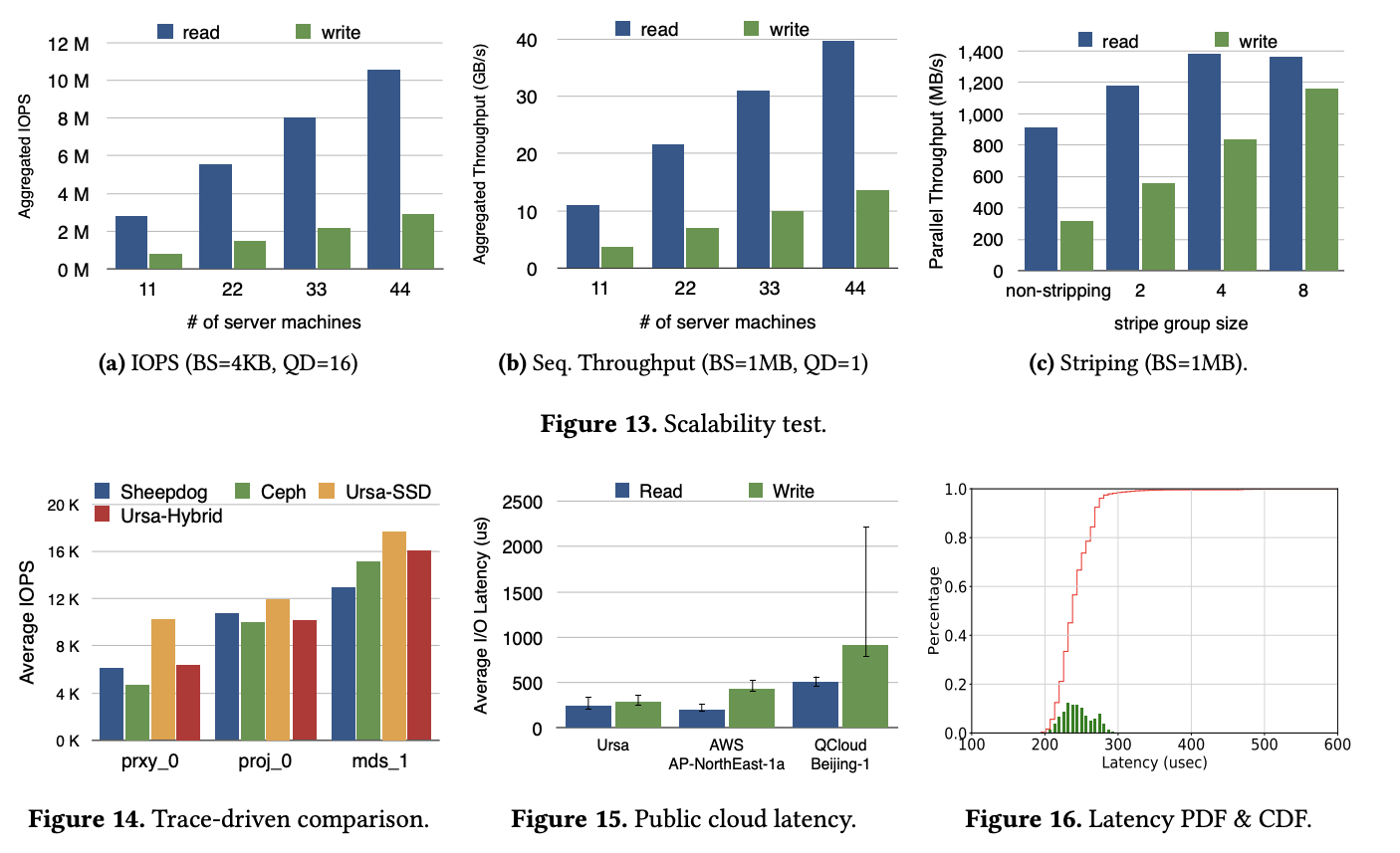
上图是 Ceph 的大致架构,考虑到 Ceph 架构的介绍文章很多,这里就赘述了,读者可以搜索任一篇 Ceph 架构的介绍文章。
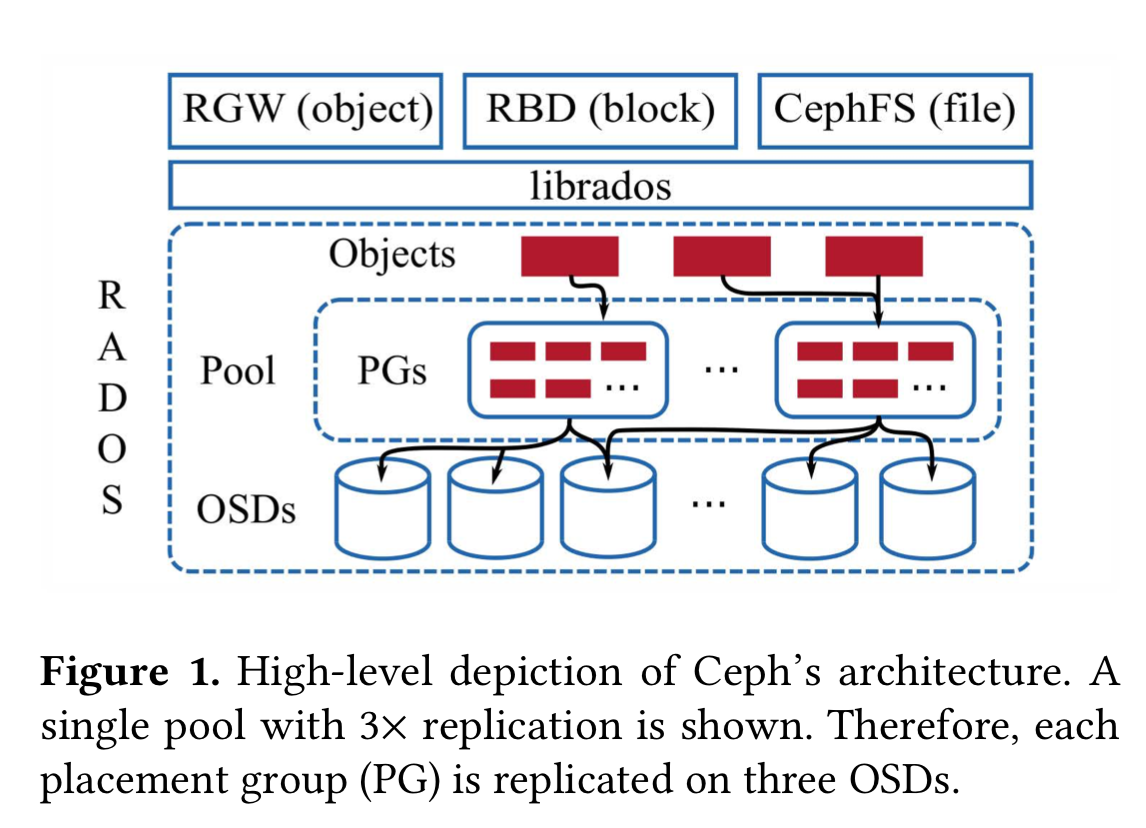
Ceph 的 ObjectStore 第一个实现是一个叫 EBOFS(Extent and B-Tree-based Object File System ) 的用户态文件系统。2018 年 Btrfs 出现,有事务、去重、校验码、透明压缩都特性,因此 EBOFS 被基于 Btrfs 实现的 FileStore 取代。
FileStore 里,一个对象集合会被映射到目录,数据会被存储到文件。一开始对象的属性是被 POSIX 的 xattrs 保存的,但后来被移到了 LevelDB(xattrs 容量有限)。
Btrfs 被用作生产环境后端很多年,这个过程中 Btrfs 一直有不稳定和数据/元数据的 fragmentation 问题,但因为对象接口的不断演进导致已经不太可能退回到 EBOFS 了,因此 FileStore 被移植到过 XFS、ext4、ZFS,最终因为在 XFS 上良好的 scale 和元数据性能而成为 FileStore 的事实标准。
虽然基于 XFS 的 FileStore 已经比较稳定了,但是一直受元数据 fragmentation 和无法充分发挥硬件性能的问题困扰。因为缺乏原生的事务,所以用户态的 WAL 实现使用了完整数据的 journal,并受读取-修改-写入这一过程(read-modify-write workloads )的速度限制——这个正是 Ceph WAL 的典型操作过程。此外,XFS 不是一个 COW 文件系统,快照因为需要克隆操作受此影响就会很慢。
NewStore 是 Ceph 尝试通过基于文件系统解决元数据问题的第一次尝试。NewStore 不再使用目录来代表对象及合,而是用 RocksDB 保存元数据。此外 RocksDB 还用来实现 WAL,使得读取-修改-写入过程可以通过合并数据和元数据日志来加速。
这个方案整体来说就是通过文件保存数据、通过在日志文件系统上运行 RocksDB 来保存元数据。但这个方案带来沉重的一致性负担,最终促使了 BlueStore 的开发。
在本地文件系统上构建存储后端的难点
难点一 高效事务
在文件系统上实现事务有三种选择:
- Hook 到文件系统内部的事务机制
-
在用户态实现 WAL
-
使用有事务的 KV 数据库
方案一:Hook 到文件系统内部的事务机制
方案 1 的问题是功能有限,而且很多文件系统没有直接对用户暴露事务。功能有限例如没有回滚机制等。Btrfs 提供了一对系统调用使得内部的事务机制可以对用户暴露。基于 Btrfs 的 FileStore 第一版是依赖于这些系统调用的,但是它没有回滚机制导致很痛苦——具体来说,如果 Ceph OSD 在事务过程中遇到了一个 fatal 事件,例如软件崩溃或者 kill 信号,Btrfs 会提交一个部分(partial)事务,留给存储后端一个不一致状态。
Ceph 团队和 Btrfs 团队都接受的解决方法包括提供一个 entire transaction 系统调用,或者基快照实现回滚,但这两个方案都有很高的成本。最近 Btrfs 废弃掉了事务系统调用,和微软对 NTFS 的决定类似。
方案二:在用户态实现 WAL
方案二是可行的,但是受三个主要问题的影响:
- 读取-修改-写入速度
一个用户态 WAL 实现每个事务需要三步:
第一步、先对事务序列化,写入到日志;
第二步、通过 fsync 持久化日志;
第三步、执行事务内的操作
这样最终导致整个 WAL 的延迟很高,无法实现高效的 pipeline
-
非幂等操作
FileStore 中对象通过文件表示,对象集合会映射到目录。
在这种数据模型下,crash 之后重放 WAL 因为一些操作非幂等会导致很有难度。在 WAL 定时 trim 时,总会有一个时间窗口事务日志已经提交到文件系统但事务还没有完成(a window of time when a committed transaction that is still in the WAL has already been applied to the file system)。
举个例子,考虑一个事务包含三个操作:
① 克隆 a 到 b
② 更新 a
③ 更新 c
如果在第二步之后发生 crash 了,replay WAL 会破坏 b
在考虑另一个例子,事务有四个操作:
① 更新 b
② 将 b 重命名为 c
③ 将 a 重命名为 b
④ 更新 d
如果在第三个操作之后发生了 crash,重放 WAL 会破坏 a(也就是现在的 b),然后因为 a 已经不存在而失败。
基于 Btrfs 的 FileStore 通过对文件系统做周期性快照和对 WAL 做快找时间的标记来解决这一问题。当恢复时,最近的一个快照被恢复,然后 WAL 从相应时间点那一刻开始 replay。
但因为现在已经使用 XFS 来替代 Btrfs,XFS 缺乏快照带来了两个问题。首先,XFS 上 sync 系统调用是将文件系统状态落盘的唯一选择,但对一个典型的多磁盘构成的节点来说,sync 过于昂贵因为会对所有磁盘生效。这个问题已经被增加 syncfs 调用解决——只同步指定的文件系统。
第二个问题是在 WAL replay 后,恢复文件系统到指定状态会因为上面说的缺乏幂等性而产生问题。为此 Ceph 又引入了 Guards(序列号 sequence numbers )来避免 replay 非幂等操作。但庞大的问题空间导致在复杂操作下 guards 的正确性也很难验证。Ceph 通过工具产生复杂操作的随机排列,然后加上错误注入来半自动的验证正确性,但最终结果是 FileStore 的代码很脆弱而且难以维护。
-
双写。最后一个问题是数据会被写两次,一份到 WAL 一份到文件系统,减半了磁盘的带宽。核心原因是大部分文件系统都只对元数据修改记录到日志,允许在 crash 后丢失数据。然而 FileStore 对文件系统的使用(namespace、state)因为一些 corner case(例如对多文件部分写 partially written files)导致 FileStore 不能像文件系统一样只在日志中记录元数据修改。
尽管可以说 FileStore 这种对文件系统的使用是有问题的,但这种选择也有技术原因的。如果不这么做就需要实现数据和元数据的内存 cache 以等待 WAL 的任何更新——而内核已经有了 page 和 inode 的缓存。
方案三:使用有事务的 KV 数据库
在 NewStore 方案中,元数据保存在 RocksDB,一个有序 KV 数据库,而对象数据继续在文件系统上以文件形式表示。这样,元数据操作直接在数据库执行;数据的覆盖写被记录到 RocksDB 然后延迟执行。下面介绍 NewStore 如何解决前面说到的用户态 WAL 的三个问题,然后介绍后面因为在一个日志文件系统上运行带来的极高的一致性成本。
首先,因为 KV 数据库的接口允许我们直接读取对象状态而不需要等待上一个事务完成,从而避免了缓慢的“读取-修改-写入”。
其次 replay 非幂等操作的问题通过在准备事务时在读取侧解决。举个例子,克隆 a 到 b,如果对象比较小,那么就复制一份并插入到事务,如果对象比较大,那么就是用 COW 机制,将 a 和 b 指向到同一数据,并把数据标记为只读。
最后,双写的问题也解决了,因为对象的命名空间已经和目录结构解耦,新对象的数据都会先写到文件系统然后自动添加引用到数据库。
尽管上面说了许多好处,但与 journal on journal 类似,日志文件系统与 RocksDB 的组合会带来很高的一致性开销。在 NewStore 上创建对象需要两步:
- 写入一个文件并执行
fsync
- 同步将对象元数据写入到 RocksDB,也会导致一次
fsync
理想状态下,每次fsync会导致一次昂贵的FLUSH CACHE 操作到磁盘。但实际上在日志文件系统上每次fsync会带来两次 flush command:一次是写数据,一次是文件系统提交元数据日志。这样导致在 NewStore 上创建对象会产生四次昂贵的flush操作。
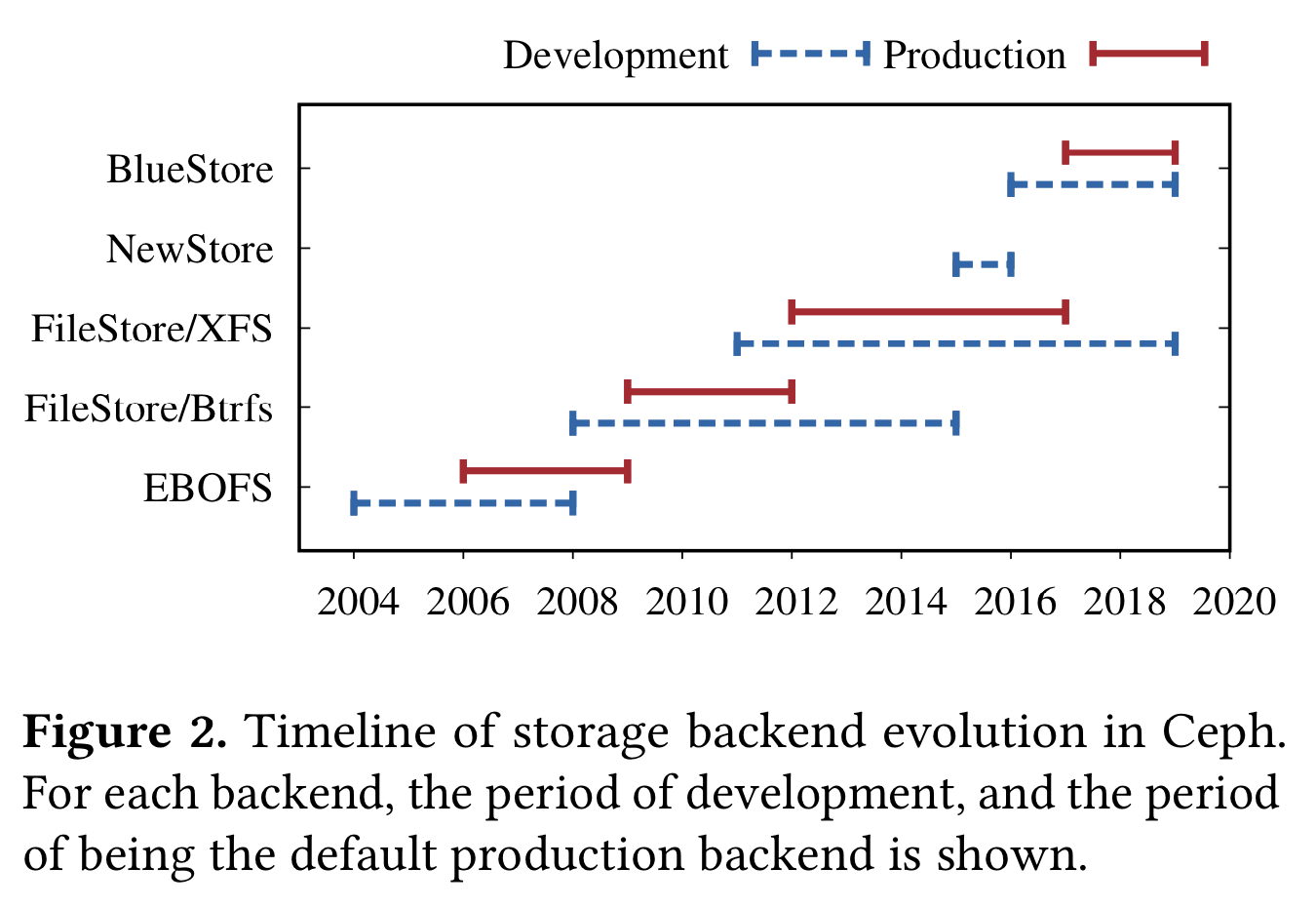
下面用一个模拟测试来展示这一开销,测试方法是模拟存储后端创建大量对象,每轮会先写 0.5MB 数据然后插入 500Byte 的元数据到 RocksDB。先模拟 NewStore (在 XFS 上)的实现,然后模拟在裸盘上的实现。
可以看到裸盘实现比 XFS 实现在 HDD 快 80%,Nvme SSD 上快 70%。
难点二 快速元数据操作
本地文件系统缺乏元数据操作可以说是分布式文件系统艰难的源泉。Ceph FileStore 元数据操作一大挑战就是本地文件系统在对大目录读取(readdir)的性能差和缺乏结果排序。
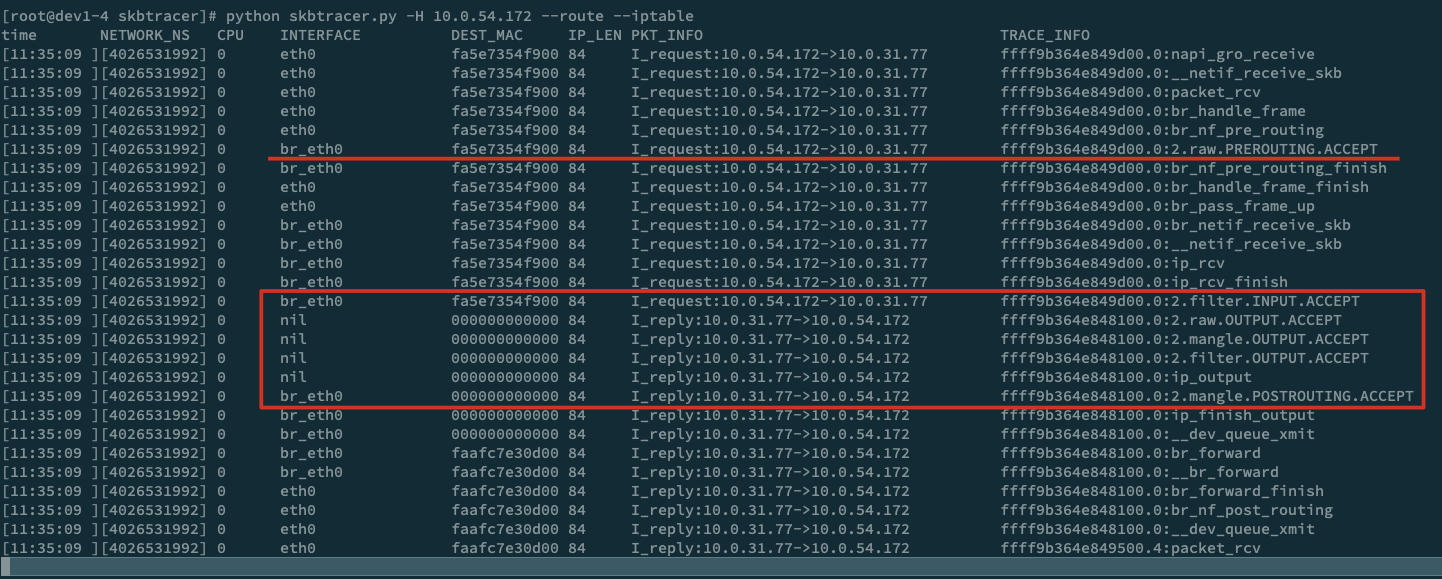
RADOS 中的对象都会根据名字哈希映射到 PG,然后按照哈希顺序枚举。对于像 scrubbing、recovery 或者 librados list 对象这些操作,这个枚举操作都是必须的。对于具有很长名字的对象,FileStore 通过文件的扩展属性来突破文件系统对名字长度的限制,这样的话就需要一个stat调用才能确定对象的名字。FileStore 采用了一个通用做法来解决这一问题:使用一个大的、散开的(large fan-out)目录层级结构,对象分布在多个目录里,然后组合读取目录的内容并排序。
为了快速排序和减少潜在的stat 操作的开销,目录要保持在比较小的规模(几百个条目这样),这样就要当数量比较大的时候对目录进行拆分。这个在规模较大时会成为一个显著影响性能的操作,有两个原因:
- 一次处理百万个 inode 会降低 dentry cache 的命中率,造成大量的磁盘小 IO;
- XFS 将子目录放在一个不同的
allocation groups里来确保将来有足够的空间把目录条目放置在一起(XFS places subdirectories in different allocation groups to ensure there is space for future directory entries to be located close together),因此随着对象数量的增长,一个目录内容的会不断散开(spread out),然后拆分目录会因为 seek 花费越来越多的时间。
最终的结果是当所有 OSD 一齐执行目录拆分时,会显著的影响性能,这个问题因为已经影响了很多 Ceph 用户数年而被广为人知。
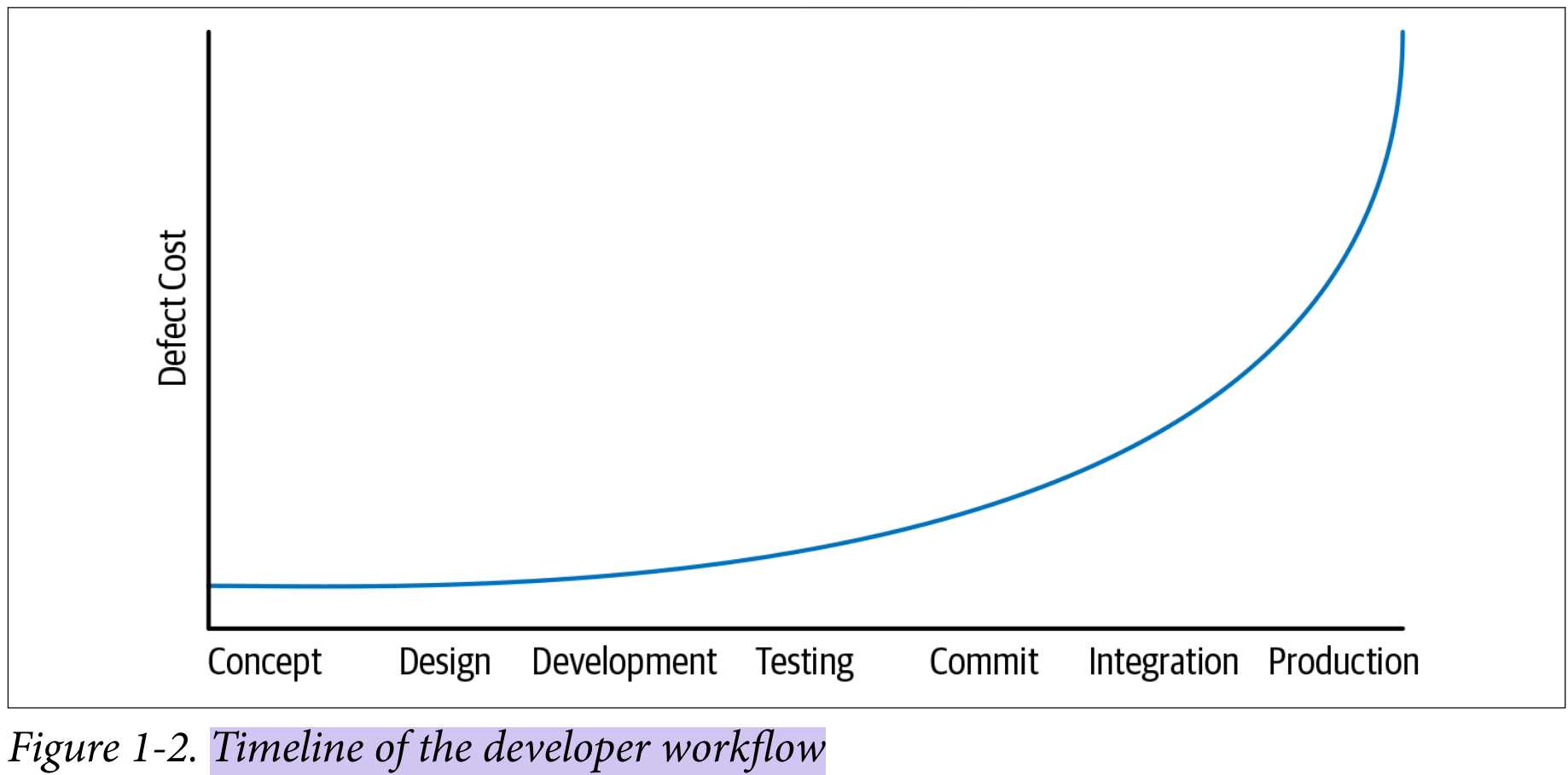
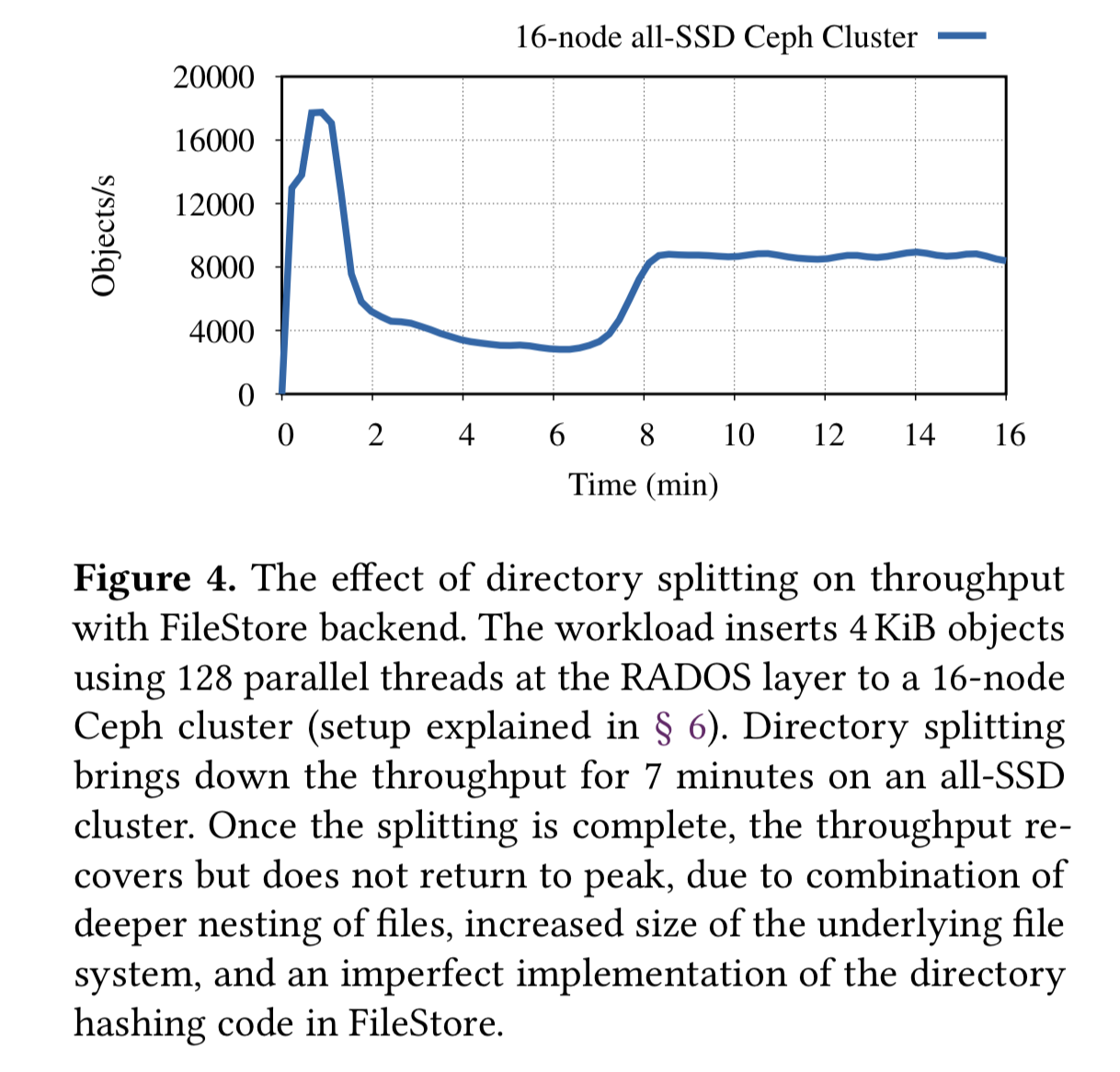
为了展示这一影响,我们配置了一个 16 节点的 Ceph 集群,将 PG 数量设置为推荐值的一半来特意增加目录拆分的压力,RADOS 层队列深度为 128,插入了百万个 4KB 的对象。下图展示了拆分目录的影响,一开始没有什么感觉,第二次拆分导致了性能的急剧下降,并在后面 7 分钟内偶有明显的性能损失,这里展示的是 SSD 集群,对于 HDD 集群,可以观察到 120 分钟的性能损失(没有展示图)。因此这造成在全 HDD 集群里,恢复操作因为seek的高开销而需要比 SSD 高一个数量级的时间成本。
难点三 对新硬件的支持
以 SMR 为例,如果使用供应商提供的向后兼容的drive-managed SMR接口,会导致性能不可预期(unpredictable performance),如果想达到预期性能,就要使用host-managed SMR提供的不向后兼容的 Zone 接口——这种接口鼓励开发者使用 log-structured、COW 的设计,与现有的成熟文件系统设计完全不同(in-place 覆盖)。
另一个例子就是 OpenCannel SSD,现在主要供应商都开始提供新的 NVMe 标准即 Zoned Namespaces 来定义无 FTL 的 SSD 的接口。去掉 FTL 有很多好处——减少写放大、改善延迟、改善吞吐、减少超分、还能通过减少 DRAM 来降低成本。
这两种新硬件目前都没有成熟的文件系统支持。
其他难点
很多公有云和私有云依赖像 Ceph 这样的分布式存储来提供存储服务,但如果没有对 IO 栈的完整控制,很难定义存储的延迟 SLO。其中一个原因是文件系统为基础的存储会使用系统的 page cache。为了提升用户体验,大部分系统都会设计基于 write-back 的 page cache,这样数据可以 buffer 在内存,当系统的 IO 很少,或者达到了预定的周期时间,就将 page cache 回写到磁盘。对于一个复杂系统,write-back 行为会受一些列复杂策略影响,导致不可预测。
对 Ceph FileStore 来说,尽管有自己周期性的fsync,但它无发现 inode 元数据的 write-back,导致性能不稳定。
再一个难点是基于文件系统的存储后端在实现像 COW 这样的操作。如果后端文件系统是 COW 的,
那么这些操作的实现会很搞笑。但是,他也有一些其他缺点,例如在 Btrfs 上会产生碎片。反过来如果文件系统不支持 COW,那么这些操作就需要成本很高的对对象完整复制,导致快照、EC 的覆盖写代价非常高昂。
BlueStore:一种全新的方法
BlueStore 是一个用来解决上面提到的各种问题的、从头开始写的存储后端,BlueStore 的一些主要设计目标包括:
- 快速元数据操作
- 对象写入时没有一致性开销
- 支持 COW
- 没有日志双写问题
- 对 HDD 和 SSD 具有优化的 IO pattern
BlueStore 用了两年时间完成了上面的所有目标,并成为了 Ceph 的默认存储后端。这么快的达成(相比通用 POSIX 文件系统需要十年计)有两个关键因素:
- BlueStore 只实现了少量的、专用的接口,而不是完整的 POSIX 标准
- BlueStore 在用户态实现,可以复用很多完整测试过、高性能的第三方代码
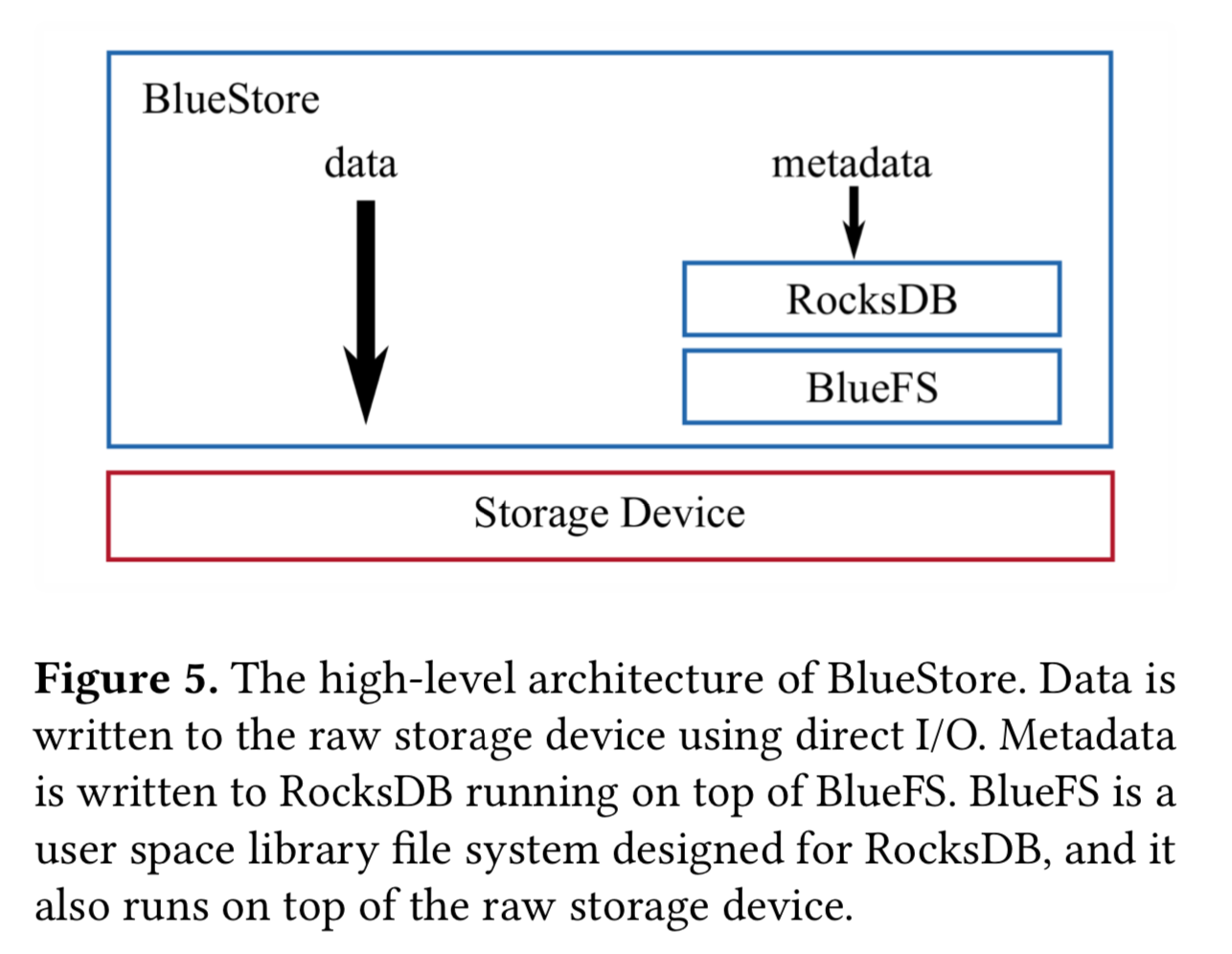
BlueStore 的整体架构如下图所示,BlueStore 运行在裸盘上,BlueSore 的 space allocator 决定新数据的位置,然后数据会通过 Driect IO 异步写入到磁盘。内部元数据和用户定义元数据被保存在运行在 BlueFS 的 RocksDB,BlueFS 是一个很小的为 RocksDB 量身定做的用户态文件系统。space allocator 和 BlueFS 会定时通讯来平衡容量。
BlueFS 和 RocksDB
BlueStore 通过将原数据保存到 RocksDB 来实现快速的元数据操作;通过下面两点来避免一致性开销:
1. 直接写数据到裸盘,从而只有一次 cache flush;
2. 修改 RocksDB 将 WAL 作为 circular buffer 使用,从而达到元数据写入只有一次 cache flush——这个 feature 已经 upstream 到上游。
BlueFS 实现了像open、mkdir、pwrite这些 RocksDB 所需的基本系统调用。BlueFS 的磁盘布局如下图。
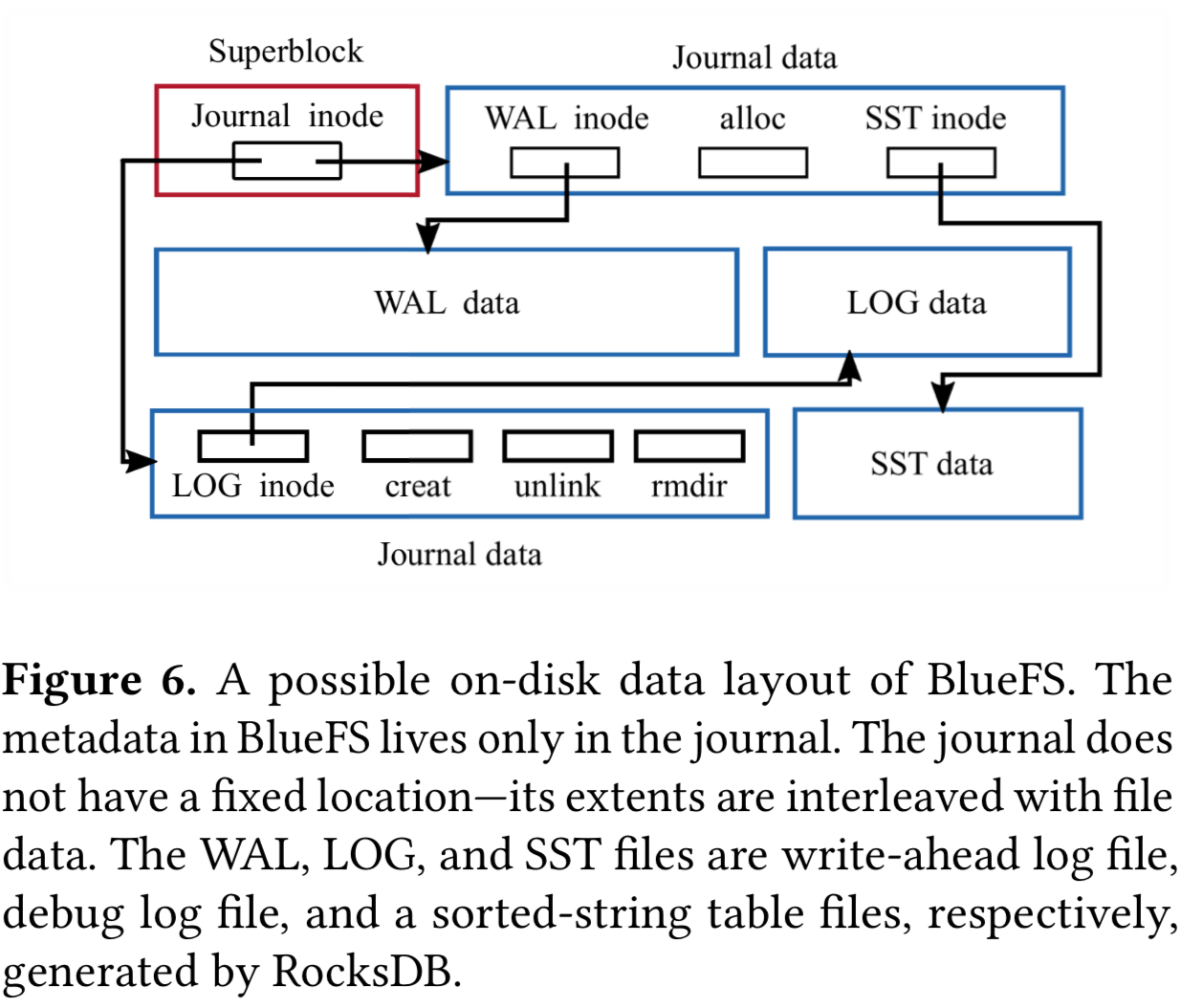
BlueFS 为每一个文件维护一个 inode,其中包含为这个文件分配的 extent 信息。superblock 保存在固定位置,包含 journal 的 inode。journal 有文件系统元数据的唯一副本,mount 时加载到内存。每当有元数据操作例如创建目录、文件和分配 extent 时,journal 和内存里的元数据会被更新。journal 不保存在固定位置,它的 extent 会与文件的 extent 有交错。每当达到一个阈值时,journal 会被压缩并写到新的位置,这个新的位置被记录到 superblock 里。这样设计之所以可行是因为得益于大文件和周期压缩会限制任一时刻 volume 元数据的数量。
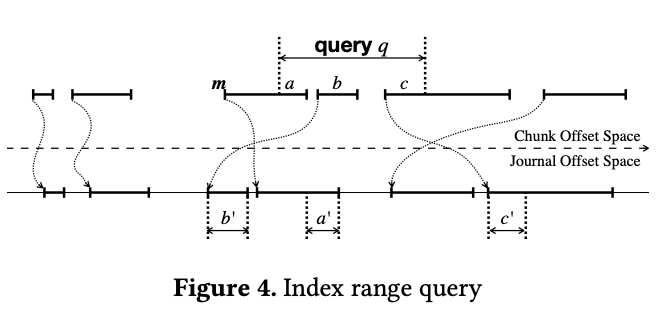
关于元数据组织,BlueStore 在 RocksDB 中使用了多个命名空间,每个命名空间用来保存不同类型的元数据。举例来说对象信息都保存在命名空间 O 中(也就是说 RocksDB 中 O 开头的 key 都表示对象的元数据),块分配元数据保存在命名空间 B,集合元数据(collection metadata)保存在命名空间 C。每个集合(collection)映射到一个 PG,并代表 pool namespace 得一个 shard。collection 的名字包含 pool 的标识和collection 里对象名字的统一 prefix。
举个例子,一个 kv:C12.e4-6标识 pool 12 的一个集合,这个集合里的对象的哈希以 e4 的 6 个最高有效位开头(hash values starting with the 6 significant bits of e4)。例如对象 012.e532 就是这个集合的成员(前六位是111001),而 012.e832 就不是(前六位是111010)。这种元数据组织方式允许只通过修改有效位数的数量(the number of significant bits)把数百万的对象分割成多个集合。这样比如有加入的 OSD 增加了总容量或者现有 OSD 因为失效从集群移除时,FileStore 在拆分 collection 时就需要昂贵的目录拆分,而 BlueStore 就简单很多。
数据路径和空间分配
BlueStore 是一个 COW 的后端。对于大于最小分配大小的写请求(对于 HDD 是 64KB、SSD 是 16KB),数据会被分配到一个新分配的 extent。当数据持久化之后,对应元数据就会插入到 RocksDB。这允许 BlueStore 提供高效的克隆操作。克隆操作只需要增加所需要的 extent 的引用计数,然后将新写入指向到新的 extent。这允许 BlueStore 对大于最小分配大小的这部分写、部分写请求避免日志双写。
对于小于最小分配大小的写请求,数据和元数据都都会被先保存到 RocksDB 然后将来随事务异步写入到磁盘。这个延迟写的机制有两个目的:
1. 合并提交小 IO 来提高效率——写一个新数据需要两次 IO 而插入到 RocksDB 只需要一次
2. 根据设备类型优化 IO,通过在 HDD 上异步写 64KB 以下的数据来避免在读操作过程中 seek(avoid seeks during reads),再 SSD 让原地覆盖写(in-place overwrite)仅发生在 16KB 以内的 IO。
关于空间分配,BlueStore 使用两个机制来分配空间:FreeList manager 和 Allocator。FreeList 作为一个磁盘当前使用的持久化记录。就像 BlueStore 的所有元数据一样,它首先被保存到 RocksDB。FreeList manager 的第一版实现被设计为通过 offset 和 length 的键值对表示已使用的 region。这个设计的缺陷在于必须对事务进行序列化——为了避免 free list 不一致,需要先删除旧的 key,然后插入新的 key。第二版设计为基于 bitmap。分配和回收操作使用了 RocksDB 的 merge 操作符来反转受影响的 block 所对应的 bit,从而消除了排序这一要求。RocksDB 中的 merge 操作符执行延迟的、原子的读取-修改-写入操作(deferred atomic read-modify-write operation),与原方法相比不会改变语义也不需要查询的开销。
Allocator 负责为新数据分配空间。他保存了一份 free list 的内存拷贝,并且会在分配后通知 FreeList Manager。Allocator 的第一版实现是基于 extent 的,将可用 extent 划分到 2
的 n 次幂的容器中(power-of-two-sized bins)。随着磁盘使用量的增加,这个设计容易产生碎片。第二个设计使用索引结构,这个结构在一个“一位表示一个 block”(single-bit-per-block)的描述之上来跟踪块的所有区域(track whole regions of blocks)。通过查询高层和低层索引,可以有效的找到大的和小的 extent。这种实现对每 PB 使用固定的 35MB 内存。
关于 Cache,因为 BlueStore 实现在用户空间且通过 Direct IO 访问磁盘,所以它不能够利用到操作系统的 page cahce。所以 BlueStore 在用户层使用 scan resistant 2Q 算法实现了自身的 write-through 缓存。缓存通过 shard 来并发。它使用了和 Ceph OSD 一样的 shard 模式,对到多个集合的请求通过不同 core 来 shard。这样避免了 false sharing,这样同一个 CPU 的上下文始终访问它对应的 2Q 数据结构。
得益于 BlueStore 所实现的功能
本节会介绍由于具备了对 IO 栈的完整控制后,BlueStore 所能实现的过去无法实现的功能。
高空间利用率的 checksum
Ceph 会每天 scrub 元数据、每周 scrub 数据,但即使有 scrub 机制,数据如果在不同副本间不一致也很难确定哪个副本是受损坏的那个。因此 checksum 对分布式存储很重要,特别是对于 PB 级的数据,几乎是必然会发生位翻转这些错误。
绝大多数本地文件系统是不支持 checksum 的。一些支持的,比如 Btrfs,会对每 4KB 计算校验和以方便覆盖写 4KB block。那么对于 10TB 的数据,为每 4KB 数据存储 32 位的 checksum 需要最终占用 10GB 的空间,这将导致难以将 checksum 缓存到内存来做快速验证。
另一方面,大部分存在分布式文件系统的数据是只读的,可以以更大粒度来计算 checksum。BlueSTore 对每次写请求计算一个 check,并且在每次读取时计算。BlueStore 支持多种 checksum 算法,其中 crc32c 是默认选项——因为它在 x86 和 arm 上都有良好的优化,而且也足以探测随机的位错误。由于对 IO 栈的完整控制,BlueStore 可以根据 IO 迹象(hint)来选择 checksum 的 block size。举例来说,如果根据 IO 推测写请求来自 S3 兼容的 RGW 服务,那么对象是只读的,checksum 可以以 128KB 为粒度计算。如果 IO 是需要压缩的对象,那么 checksum 在压缩后计算,显著的减小了 checksum 的大小。
EC 数据的覆盖写
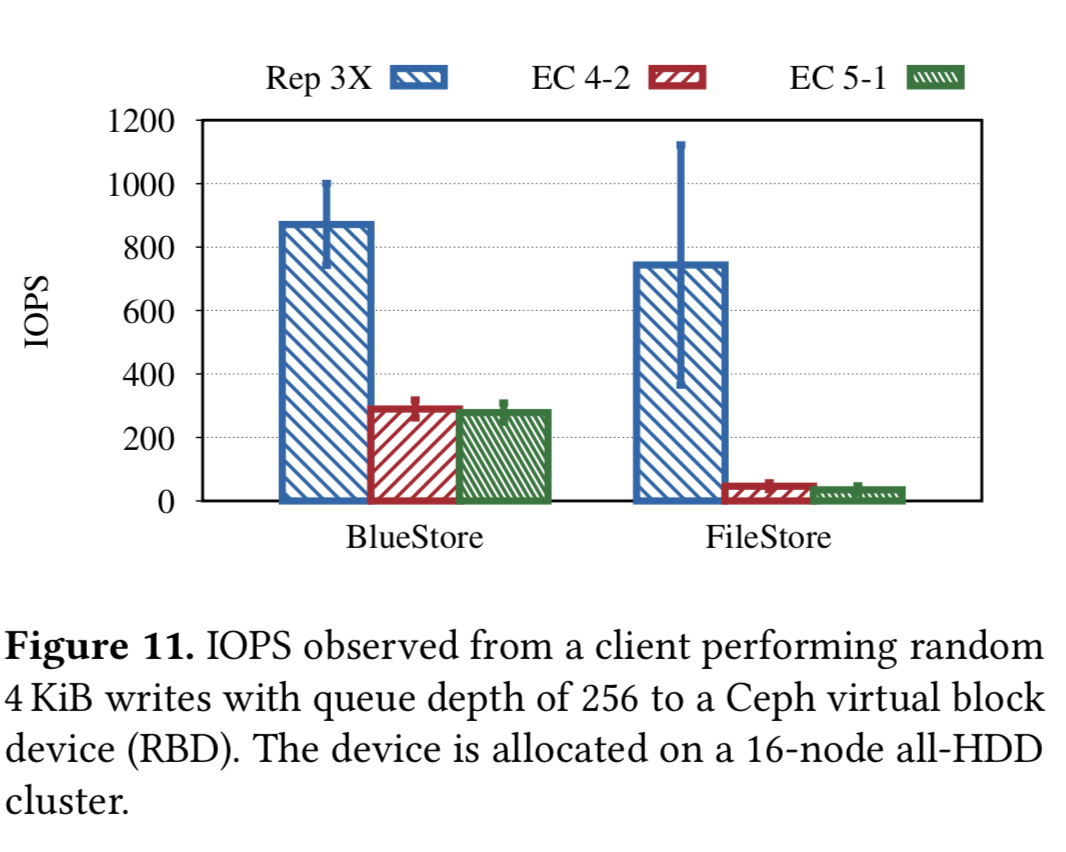
Ceph 从 2014 年 FileStore 就支持了 EC pool,然而这个支持仅限追加写和删除操作,因为覆盖写在这个设计下太慢了,几乎无法使用。结果是,EC 池尽在 RGW 场景有用,对于 RBD 和 CephFS 是无法使用。
为了避免 Raid write hole 问题,多步骤的数据更新时,如果发生 crash 会导致系统不一致,Ceph 在 EC 池的覆盖写使用两阶段提交。首先,所有存储这个对象的一个 chunk 的 OSD 都会复制这个 trunk 来为失败回退做准备。当所有 OSD 收到新的数据内容要覆盖写 trunk 时,旧的 trunk 副本就会被丢弃掉。在 XFS 为基础的 FileStore 下,第一步是非常昂贵的,因为需要一次物理复制。而对 BlueStore 来说得益于 COW 就避免了完整的物理复制。
透明压缩
透明压缩对横向扩展分布式文件系统是很关键的,因为 3 副本会增加存储的成本,BlueStore 实现了透明压缩,在写数据时会在其落盘前自动压缩数据。
要充分发挥压缩衣的优势,需要被压缩的 chunk 至少是 128KB 以上,而且是对整个对象压缩。对于压缩对象的覆盖写,BlueStore 会先把放在单独为止,然后更新元数据指向到它。当压缩对象碎片化比较严重时,BlueStore 会执行 compact 操作。实践中,BlueStore 会使用简单的启发式策略和 hint 只压缩那些不大可能会被覆盖写的对象。
新接口
因为不受本地文件系统的 block-based 设计约束,BlueStore 在探索新的接口和数据分布上有了更高的自由度。最近,RocksDB 和 BlueFS 已经被移植到 host-managed SMR 上,而在这类设备上存储数据也已经在作为下一个努力方向。此外 Ceph 社区还在探索一些新的后端,尝试将持久化内存和新的 NVMe 设备组合,例如 ZSN SSD 和 KV SSD。
评估
以下评估都是在 16 节点通过 Cisco 3264-Q 交换机连接起来的 Ceph 集群,每个节点有一个 16 核 E5-2698Bv3 2Ghz 处理器,64GB 内存,400GB P3600 NVMe SSD,4TB 7200 RPM Segate HDD,Mellanox 40Gb 网卡。系统是 Ubuntu18.04,内核为 4.15,使用 Luminous 版本(v12.2.11),使用 Ceph 默认配置。
直接对 RADOS 测试
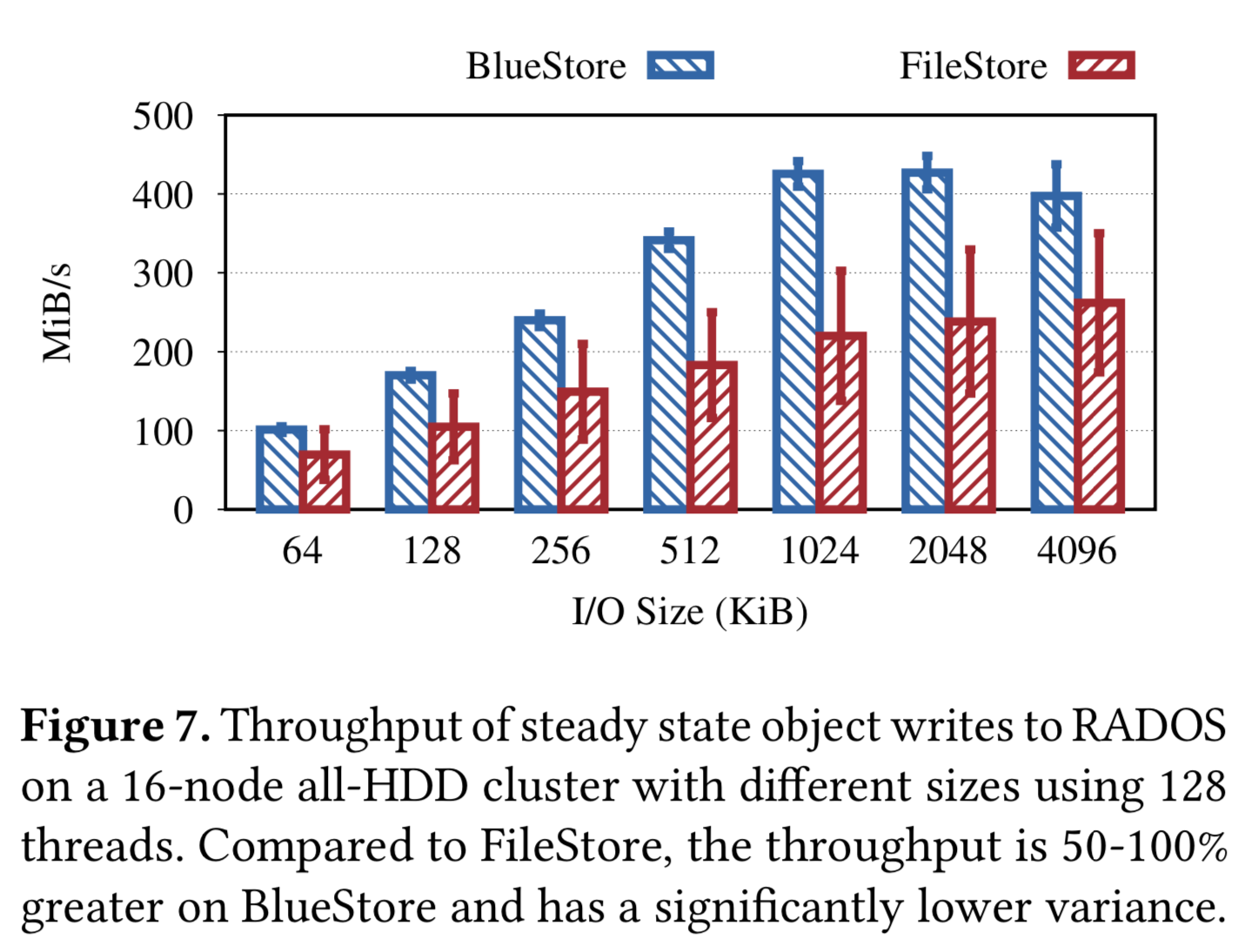
写吞吐数据:
写延迟数据:
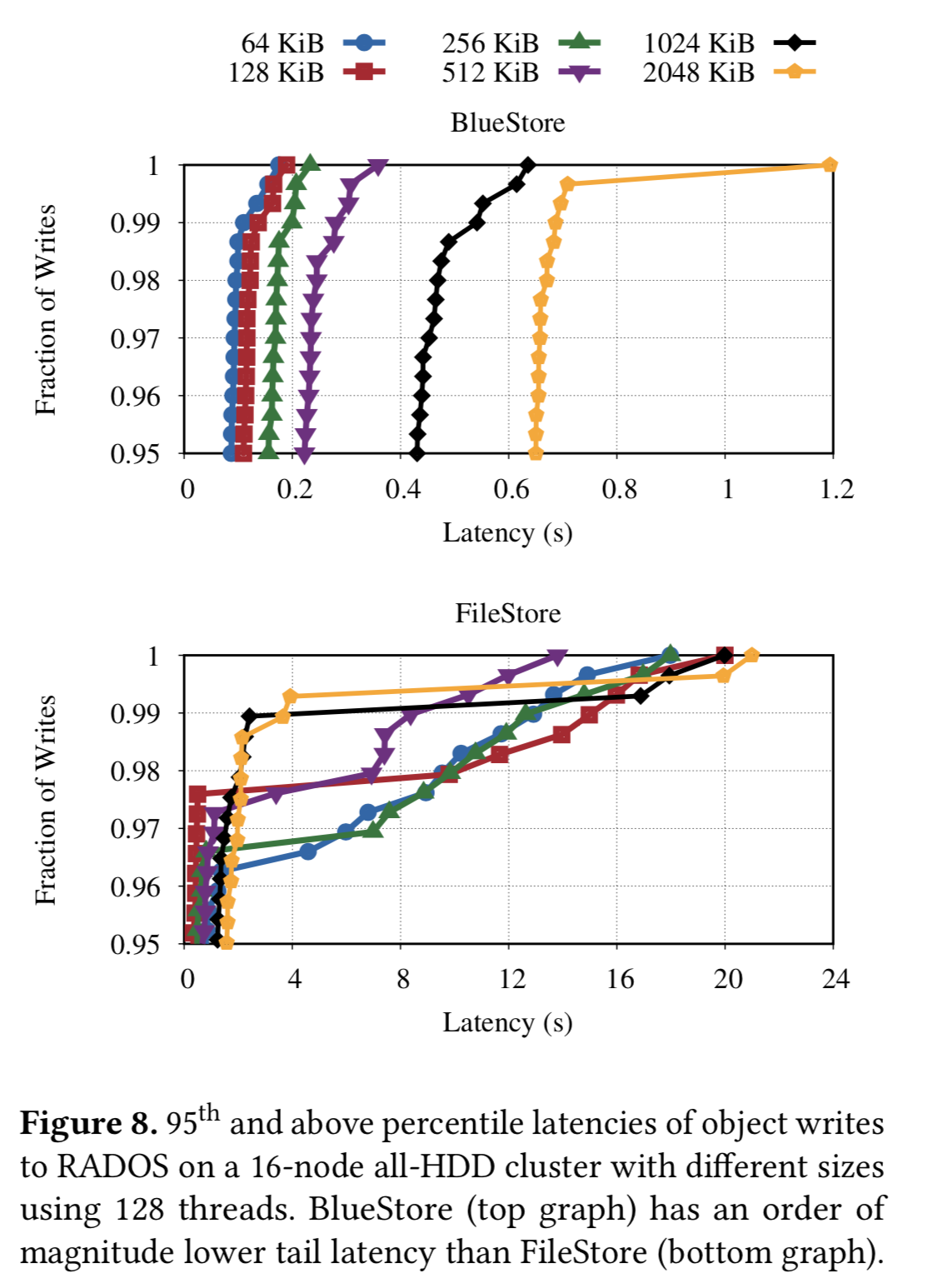
在读性能上 BlueStore 没有表现出优势,因为 FileStore 实现了 Read ahead,而 BlueStore 可以没有实现。
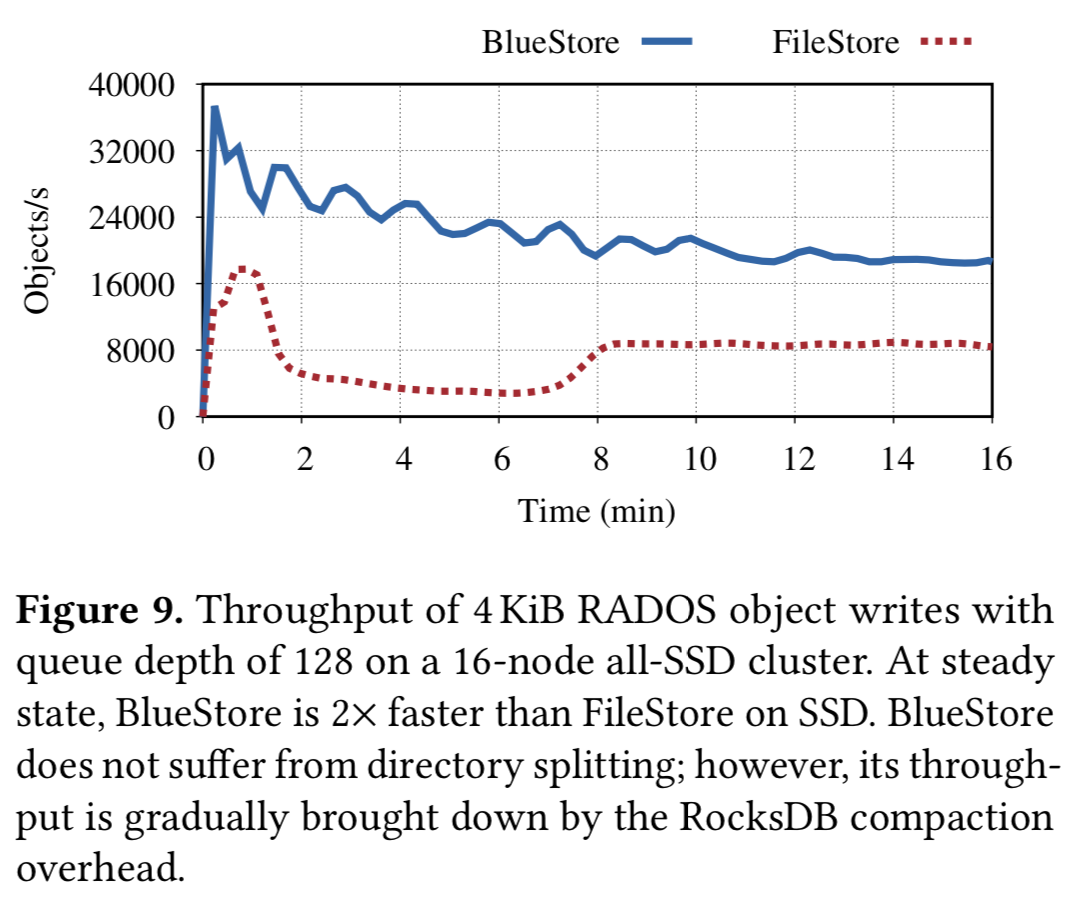
前面提到的拆分对 FileStore 的影响与 BlueStore 在相同条件下做对比,BlueStore 前面的性能下降是因为 RocksDB 的 compact 影响没有到达一个稳定状态:
RBD块设备测试
测试前会 drop 系统 cache 和重启 BlueStore OSD 来避免 cache 的影响。
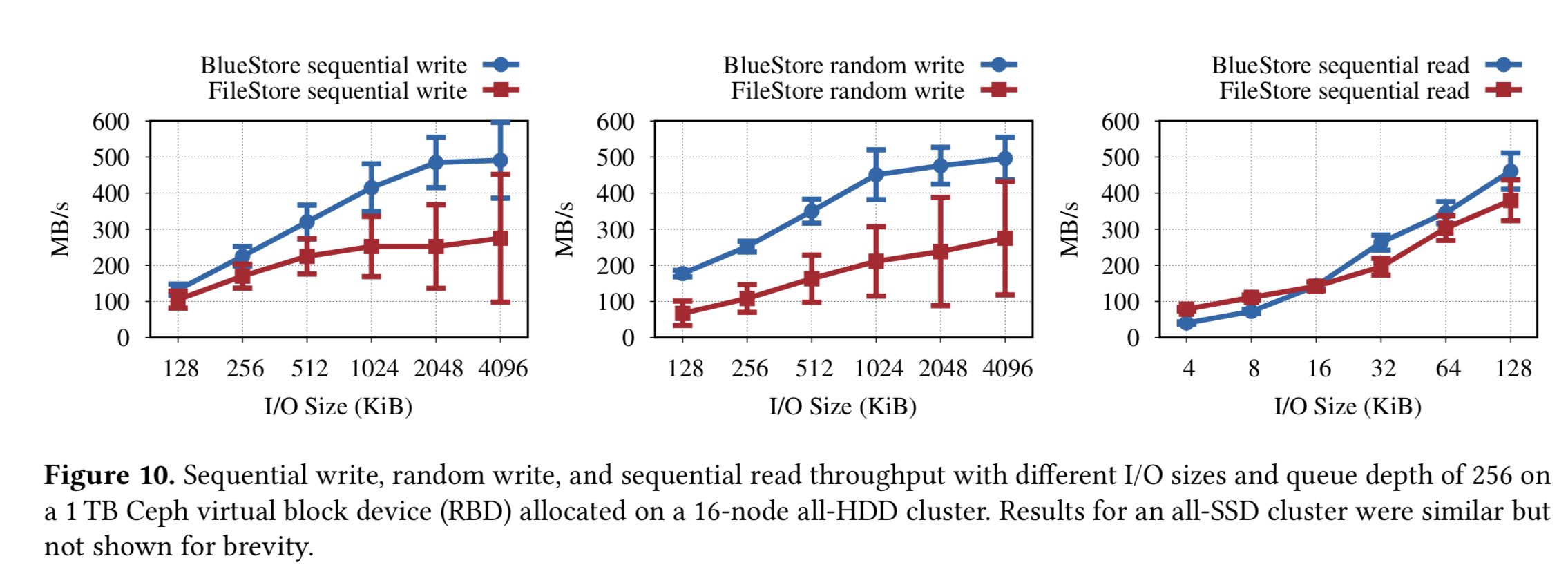
可以看到首先 BlueStore 的吞吐更好——这个很大一部分来源于规避了双写,其次方差更小——因为 BlueStore 直接将数据写入磁盘,而 FileStore 的系统 write back 触发和 Ceph 前台 WAL 相冲突引起较长的 latency。
对于小于 64KB 的写请求,BlueStore 要比 FileStore 好 20%,因为 BlueStore 会将数据写入到 RocksDB 就返回。(MatheMatrix:无图)
在读性能上 BlueStore 没有表现出优势,和前面一样,因为 FileStore 实现了 Read ahead,而 BlueStore 可以没有实现。
EC数据的覆盖写
在裸设备上实现高性能存储后端所面临的挑战
cache 大小和 writeback
文件系统可以直接利用内核的 Page Cache,但基于裸设备的存储就得自己从头实现类似的机制。具体参考4.2 节。
高效的 KV 存储
Ceph 团队的经验是将所有元数据放到有序的像 RocksDB 这样的 KV存储可以有效提高原数据性能。然而,在整合过程中也遇到一些问题:
- RocksDB 的 compact 写放大和导致无法充分使用 NVMe 的性能;
- 因为把 RocksDB 视为一个黑盒,因此序列化和反序列化数据花了更多的 CPU 时间;
- RocksDB 有自己的线程模型,限制了自定义 sharding。
高效的 CPU 和内存使用
现代编译器会对内存里的数据做 align 和 pad 来提高 CPU 读取的性能,但对复杂的数据结构,这种做法会浪费大量内存。对大部分应用这件事都不需要太过关心,因为他们的内存里的数据结构生命周期都很短。但对于绕过 page cahce 的存储后端,长时间这么运行会几乎占掉机器所有的内存,Ceph 团队花了很久时间,主要通过 delta and variable-integer encoding 等技巧 pack 保存到 RocksDB 的元数据来减少元数据大小和降低 compact 的开销。
另一个问题是在高端 NVMe 设备上,BlueStore 性能受 CPU 所限制,因此对于下一代后端,Ceph 社区在探索减少对 CPU 的使用,例如降低数据的 serialization-deserialization、结合使用 SeaStar 和 shared-nothing 模型——避免 lock 造成的上下文切换。
相关工作
关于事务,in-kernel 实现可以参考 Btrfs、NTFS、Valor、TxFS 等,基于用户文件系统的数据库可以参考 Amino(基于 Berkerly DB)、Inversion(基于 Postgres),操作系统级的实现可以参考 QuickSilver、TxOS。
关于元数据优化,相关工作有很多,例如 BetrFS、DualFS、hFS、FFS、TableFS、DeltaFS。后两者将元数据保存在 LevelDB 之上。
总结
大部分分布式文件系统都是基于本地文件系统实现,然而却导致了极大地复杂性,这种要基于本地文件系统设计的信念源于从头实现成本巨大,需要十年以上才能成熟。而 Ceph 的经验告诉我们这种想法并不准确,而且带来了——性能优势、支持新设备、通过对完整 IO 栈的控制实现过去难以实现的 feature。